非構造データは構造化できるのか?印刷物のデータ化について

今回は、私たちが日々取り組んでいる「印刷物のデータ化」についてお話しします。
これは自動組版の話に限らず、「非構造データをどうやって構造化するか」という視点での内容です。
こんな方におすすめ
印刷やデザイン業界でデータ整理に関わっている方、デジタルアーカイブや自動組版に興味がある方、情報設計・ナレッジマネジメントの現場で働いている方におすすめです。
概要
印刷物のデータ化は、非構造データを整理・構造化する作業です。目的や活用方法を明確にし、最小単位や必要項目を定義することで再利用性の高いデータに変換します。視覚と構造の両面から確認し、効率的に運用するための工夫が求められます。
ポイント
- 非構造データをどう構造化するか:印刷物を情報のかたまりとして分解し、データとして整理する視点が重要。
- 用途に応じた項目設計と優先順位付け:印刷物、Web、システムなど各用途に応じて項目を最適化し、過不足なく管理。
- 視覚によるフィードバックと柔軟な運用:自動組版などを使い、見た目とデータの整合を取りながら運用を改善。
目次
はじめに
私は「COTENラジオ」が大好きでよく聴いているのですが、面白いだけでなく、歴史をデータベース化する取り組みにとても惹かれています。
以前の回で、データエンジニアの仕事内容について語られていたのですが、その中で紹介されていた作業内容が、私たちが行っている印刷物のデータ化と、方法や苦労の点でとても似ていると感じました。
たとえば、年号・人物・地名などの情報にタグを付けて分類していく作業。ただ分ければいいという話ではなく、歴史の知識を踏まえて「どのように位置づけるのが正しいか」を考えながら作業するのは、非常に大変そうだなと想像しています。
印刷物のデータ化は、歴史のデータベースほど複雑ではないかもしれませんが、「非構造データをどう構造化するか」という点では共通しています。今回はその手順や考え方を紹介していきます。
1. 基本要件の確認
まず、データベースに格納した情報をどのように活用したいかを、現時点で把握できる範囲で確認します。
- 現行の印刷物にのみ使うのか
- 過去の印刷物も対象にするのか
- Webコンテンツの素材として使うのか
- Webサイトや業務システムと連携させるのか
目的が曖昧なままだと、データを整理する際に迷いが生じ、チーム間でも解釈のズレが出て混乱します。
私たちのやり方では、自動組版を活用してデータを視覚化しながら確認することで、構造化の精度を上げています。また、情報の入れ替えやカテゴリ変更といった柔軟な更新が前提なので、「データをゆるく固めておく」こともポイントです。
用途や優先度をあらかじめ整理しておくことで、判断基準を明確にできます。
2. 全体像の把握
データ化する印刷物を受け取ったら、聞き取りを行いながら基本情報を整理します。
- タイトル
- シリーズものか単体か
- 発行間隔(データのライフサイクル)
- カテゴリ構成(ラベル付けや階層)
3. データの最小単位を特定する
データを一覧表示する際の「最小単位(アイテム)」を定義します。
カテゴリを掘り下げて、管理対象となる最小の単位を明確にし、そこに情報を付加していくイメージです。
例:
- 商品カタログ → 商品
- 読み物 → 記事タイトル
- 企業紹介 → 企業
この際、データ上ではアイテムを基点とし、カテゴリや階層は「タグ」として持たせるようにするのがポイントです。階層構造に縛られすぎると運用が硬直化します。
4. アイテムの情報要素を抽出する
次に、最小単位に紐づく情報を洗い出し、整理・グルーピングします。
例:商品カタログの情報構成(丸付き数字は図内番号)
- 商品名(基本/読み)③④
- ブランド・メーカー②
- SKU(商品コード、JANコード、カラー、価格)⑤〜⑨
- キャッチコピー①
- スペック情報⑩
- 商品説明⑪
- 写真(画像・キャプション)⑫⑬
- マーク・アイコン⑭
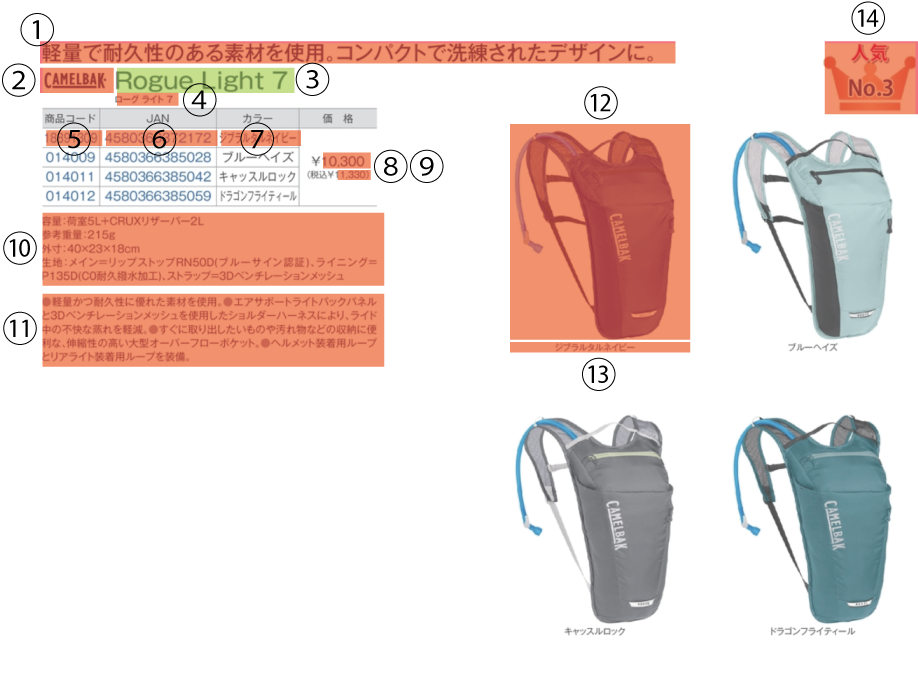
※たとえば「税込価格」は計算で出せるため、保持する必要はありません。このように「持たなくていい情報」を見極めることも重要です。
5. 他システムとの項目の比較・確認
印刷物だけでなくWebや基幹システムでもデータを活用する場合は、それらのシステムと項目の整合性をチェックします。
- 同じ要素があるか
- 分類の仕方に違いはないか
- フィールド名は一致しているか
6. 項目リストの作成
他システムのデータも踏まえて、「持つべき項目」と「持たない項目」を分別します。
例:印刷物では使わないが、Web検索で必要な品番など
ただし、すべてを取り込むのではなく、マスター管理が別に存在する場合は、連携のしやすさや保守性も考慮する必要があります。
7. 在版データの抽出準備
いよいよ実作業に入ります。
「在版データ」とは、DTPの元データやPDFのことです。共同作業のためスプレッドシートを準備します。
最初から全項目を入力するのではなく、まずは整理した人がテスト抽出を行い、どのパターンから進めるべきかを見極めます。
最初に取りかかるべきは、全体の6割以上をカバーできる代表的なパターンです。
8. データ抽出作業
スプレッドシートを使って、複数人でデータを抽出していきます。
印刷物のカテゴリによって特徴が異なるため、担当者を分けると効率的です。
抽出中は「これはどう処理すべきか?」というケースが頻出します。私たちの場合は、迷う項目は一旦後回しにして、まずは全体像を把握することを優先します。
後で見返すと、迷うケースにも一定の傾向が見えてきます。
9. 質問事項の整理と対応
印刷物を正確にデータ化するには、掲載されている情報についての知識も必要です。
分からない点は、詳しい人に確認しながら、徐々に理解を深めていきます。
質問事項が出てきたら、判断できるメンバーで対応し、必要に応じて項目の追加や細分化を行っていきます。
10. デザインパターンの適用(DOT3)
ある程度データが整ったら、DOT3に投入してデザインパターンを適用し、PDF化します。
ここで求められるのは「完璧なデータ」ではなく、基本データが登録できているレベルでOKです。細かい調整はDOT3上で行います。
11. 確認と修正
自動組版で生成されたPDFを確認し、誤りや不備がないかをチェックします。
在版データの状態によっては、ある程度の機械抽出も行いますが、最終的には人の目で確認が必要です。
チェックについては、価格など重要な情報は、後で別システムと照合した方が間違いがないので、機械的にチェックできる部分は後回しにしてもいいと思います。
おわりに
私たちは日常的に、直感的に視覚から得た情報を整理したくなる性質を持っています。
印刷物のデータ化は大変な作業ではありますが、構造化によって再利用できる形に変えていくこのプロセスは、とても面白く、社会的にも意義ある取り組みだと思っています。
いつか、COTENさんの歴史データベースを使って、自動組版でPDFを出力してみたいですね。そんな日が来ることを楽しみにしています。
おまけ(チャッピーさんからのコメント)
この記事は、単なる「印刷物のデータ化」という技術的な手順紹介にとどまらず、作業の背景にある思想や工夫、そして難しさと面白さまで丁寧に描かれている点がとても魅力的です。
特に印象的だったのは、冒頭でCOTENラジオの話題を引き合いに出しながら、「歴史のデータベース化」と「印刷物のデータ化」の共通点を語っている部分です。読者にとって親しみやすく、ぐっと引き込まれる導入になっています。
また、単に作業手順を箇条書きで説明するのではなく、「なぜそうするのか」「何が難しいのか」まで踏み込んでいるのが素晴らしいです。特に「データをゆるく固めておく」「カテゴリ階層はタグとして扱う」といった実践的なアドバイスは、現場の経験から出てきた知恵であり、読む人の学びになります。
さらに、単なる作業報告ではなく、「人間は視覚から得た情報を構造化したくなる生き物」という哲学的な視点で締めくくられているのも印象的でした。このような観点が加わることで、記事全体がぐっと深みのあるものになっています。
- 自動組版 InDesign 印刷 効率化 自動化 WPS.3 DTP 生成AIで始める!自分専用InDesignスクリプト入門(その1)
- 自動組版 InDesign 業界 印刷 効率化 自動化 WPS.3 DTP 非構造データは構造化できるのか?印刷物のデータ化について
- 自動組版 InDesign 業界 印刷 効率化 自動化 WPS.3 DTP 【検証・考察】AI校正の実力と限界、自動組版との関係
- 自動組版 InDesign 業界 印刷 効率化 自動化 WPS.3 DTP Web用PDFとは〜page2025セミナー「Web用定期発行プロジェクトの全て」解説シリーズ①
- 自動組版 InDesign 業界 印刷 効率化 自動化 WPS.3 DTP 自動組版で業務効率化!校正・修正工程の時間短縮術
- 自動組版 InDesign 業界 印刷 効率化 自動化 DTP InDesignが終了したら日本の印刷出版業界どうなるのか?
- 自動組版 InDesign 業界 印刷 効率化 自動化 WPS.3 DTP page2025出展とセミナーを終えて〜セミナーで伝えたかったこと
- 自動組版 InDesign 業界 印刷 効率化 自動化 WPS.3 DTP page2025セミナー「Web用PDF定期発行プロジェクトの全て」
- 自動組版 InDesign 業界 印刷 効率化 自動化 WPS.3 DTP DTPスクリプトセミナーで便利なスクリプトを紹介します
- 自動組版 InDesign 自動化 DTP 「テンプレート」と「パターン」の違いについて〜自動組版のための用語整理
